












- 商用クラウドAPIの利用時に課題となる「機密データの外部送信リスク」や「従量課金コスト」をクリアするため、完全ローカル環境で動作する情報検索(RAG)システムを構築
- Googleの「Gemma 4」や日本語特化の「Ruri」を組み合わせ、限られた計算リソースでも高い検索精度を維持できる「要約と本文の二段階検索」を実装
- 実運用時の最大の壁となる「起動・インデックス構築の待機時間」に対し、DB(LanceDB)のメタデータを用いた差分検知とバッチ処理を導入することで、2回目以降のインデックス処理を1秒未満(回答生成まで約40秒)に短縮
- WindowsやArch Linux環境をベースに、パッケージマネージャ「uv」を活用してチーム間で同一の実行環境を瞬時に構築できるハンズオン手順を公開
こんにちは!私は、TSUNAGU Community Analytics(以下、TCA)にて、AIモデルの構築やデータ分析業務を行っています。今回は、ローカルLLMを用いた RAG (Retrieval-Augmented Generation) 環境の構築、ハンズオン、及びその技術的知見について共有します。
なぜこのテーマか?
昨今、多くの企業において生成AI活用が注目されていますが、商用クラウドAPIの利用には、機密データの送信に関するセキュリティ制約が常に付きまといます。このような制約に対し、ローカルLLMを用いたRAG(以下、完全ローカルRAG)を用いることで機密データを安全に活用することが可能になります。しかし、完全ローカルRAGの利点は、単なる「隠蔽」だけではありません。 次のようなものが完全ローカルRAGの利点となります。
- データ主権の確保:自社サーバー内で完結するため、ガバナンスが極めて強固にできます。
- コストの最適化:ハードウェアの初期投資はあるものの、API利用料のような実行ごとの従量課金が発生せず、長期的な検証/運用や大量バッチ処理に向きます。
- カスタマイズ性:特定の業務ドメインに特化したモデルの差し替えや、推論プロセスの透明性を担保できます。
もちろん、ローカル環境ゆえのトレードオフとしての課題も存在します。ネットワーク遅延(通信レイテンシ)は回避できるものの、計算リソースが限定的なノートPC等では、推論実行時の処理時間が課題となります。しかし、GoogleのGemma 4に代表される軽量かつ高性能なローカルLLM (Large Language Model) モデルの登場により、「ある程度の速度/リアルタイム性を許容してでも、安全かつ低コストに社内資産を処理する」という実務的な選択が現実味を帯びてきました。 そこで今回は、昨今目覚ましい成長を遂げているローカルLLMを用いて、完全にローカル環境で動作し、社内情報の検索を行える「完全ローカルRAG」について検証しました。
技術的なポイント
今回は、単なるRAGの実装にとどまらず、案件や簡易検証でも流用できるよう、実運用を見据えた以下の設計を採用しました。
1. 二段階検索 (Two-stage RAG) による「精度」と「効率」の両立
通常のRAGでは、膨大な文書を機械的に分割(チャンク化)して検索するため、文脈が断片化し、ノイズを拾いやすいという課題がありました。本プロジェクトでは、あえて「要約」と「本文」の二段階構造を採用しています。
- 第一段階(コンテキストの絞り込み):まず各ファイルの「要約インデックス」を検索します。これにより、ファイル全体の趣旨を捉えた状態で、関連性の高いドキュメントを「点」ではなく「面」で特定します。
- 第二段階(詳細情報の抽出):特定されたファイルの中身(本文インデックス)に対してのみ詳細検索を行うことで、回答の根拠となる正確な記述をピンポイントで抽出します。
このアプローチにより、計算リソースの限られたローカル環境においても、大規模な文書群からノイズを排除し、実務に耐えうる高精度な回答生成を可能にしました。
2. 運用のストレスを無くす「差分更新」と「バッチ処理」の最適化
ローカル環境での最大の課題は、ドキュメント量が増えた際の「起動の重さ」です。本実装では、Embedding(ベクトル化)のプロセスを最適化しています。
- 差分検知:起動時にDB(LanceDB)のメタデータを参照し、新規/変更ファイルのみを抽出します。更新がない場合は構築プロセスをスキップし、1秒未満で起動します。
- バッチ処理:IngestionPipeline を活用し、複数文書を一括処理します。CPUのリソースを最大効率で利用し、1ファイルあたりの計算時間を劇的に短縮しました。
3. モダンなPython開発環境
依存関係管理には、高速かつ堅牢な uv を採用しました。Arch Linux や Windows といった、異なる OS 間でも、ロックファイルを用いた同一環境の構築を瞬時に行うことができるため、チーム開発における再現性の確保と導入障壁の低減を図っています。
4. ライブラリ・ソースコードの品質担保
Bandit による静的解析を実施し、脆弱性診断を行っています。また、サプライチェーン攻撃等のリスクを鑑み、LLM や Embedding モデルのロードにはコミットハッシュによる固定(Pinning)を適用します。実運用を想定したセキュリティリスクの最小化を徹底しました。
クラウドAPI(商用モデル)との比較
ローカルRAGを導入するにあたり、商用クラウドAPI(GPT-5等)との比較として以下に整理しました。それぞれの特性を理解し、用途に合わせて使い分けることが重要です。

精度の面では巨大なパラメータを持つクラウドモデルに分がありますが、実務においては以下の点がローカル環境の大きなアドバンテージと考えます。
- 心理的/法的な障壁の撤廃:機密情報を「1文字も外に出さない」という安心感は、セキュリティ審査の厳しい社内情報の取り扱いにおいて決定的な差となります。
- 試行回数の担保:課金を気にせず、数万件の文書に対して何度でもバッチ処理(一括検索や要約)を回せるため、現場でのトライ&エラーを加速させます。
- 体感的な「軽さ」:今回実装した「差分更新機能」により、変更がない時は1秒未満で起動します。インターネットを介さないため、認証待ちや通信ラグのない「手に馴染む」ツールとしての運用が可能です。
ハンズオン手順
当該記事用に作成したGitHubリポジトリ からcloneするだけで誰でも構築/ハンズオン可能です。詳細はREADMEに記載しておりますが、ざっと以下です。
1. Hugging Faceトークンの設定
- ① まずはこちらにアクセス
- ② ”Create new token” ボタンを押下
- ③ “Read” タブで Token name を任意名称書き込む
- ④ “Create token” ボタンを押下
- ⑤ 後ほど設定値として使うので、token をメモ帳か何かにコピペ、もしくは、当該ページを開いておく
2. RAG実行
例えばwindows環境(コマンドプロンプトを使用)であれば、以下を実行することでローカルRAGを体験することが可能です。

※前提としてPython, Git, VC++再頒布パッケージは既にインストールされており、gitのユーザー名/アドレス設定は完了しているものとしています。
上記スクリプトを実行すると、以下ステップが自動的に行われます
- ① ダミーデータのダウンロード:検索対象となるテキストデータを自動取得します。
- リポジトリ例では、フリーの国会文書データから "スタートアップ" というキーワードでヒットするデータを取得します。
- データは `data/dummy/kokkai/` に .txt 形式で保存されます。
- ② モデル構築:LLMおよび Embedding モデルを Hugging Face よりローカルにダウンロードし、このローカルに保存したファイルを読み込みます。(モデルはモダンな構成としました)
- ③ インデックス作成:要約用インデックス(高速検索用)と本文用インデックス(詳細検索用)の2段階を構築します。 (※初回のみ全件処理(1ファイル数秒程度)が走りますが、2回目以降は差分検知により即座に完了します。)
- ④ 二段階検索の実行:要約インデックスで関連性の高いファイルを特定し、その内容を本文インデックスで詳細に検索します。
- ⑤ 回答生成:検索結果を基にモデルが回答を生成し、data/output/{YYYYmmdd-HHMMSS}/output.txt に結果が出力されます。
検索クエリやプロンプトについてはsrc/helper/cfg.ymlにて以下のように設定しています。(サマリー作成用やその他設定値については割愛)

以下が回答結果です。

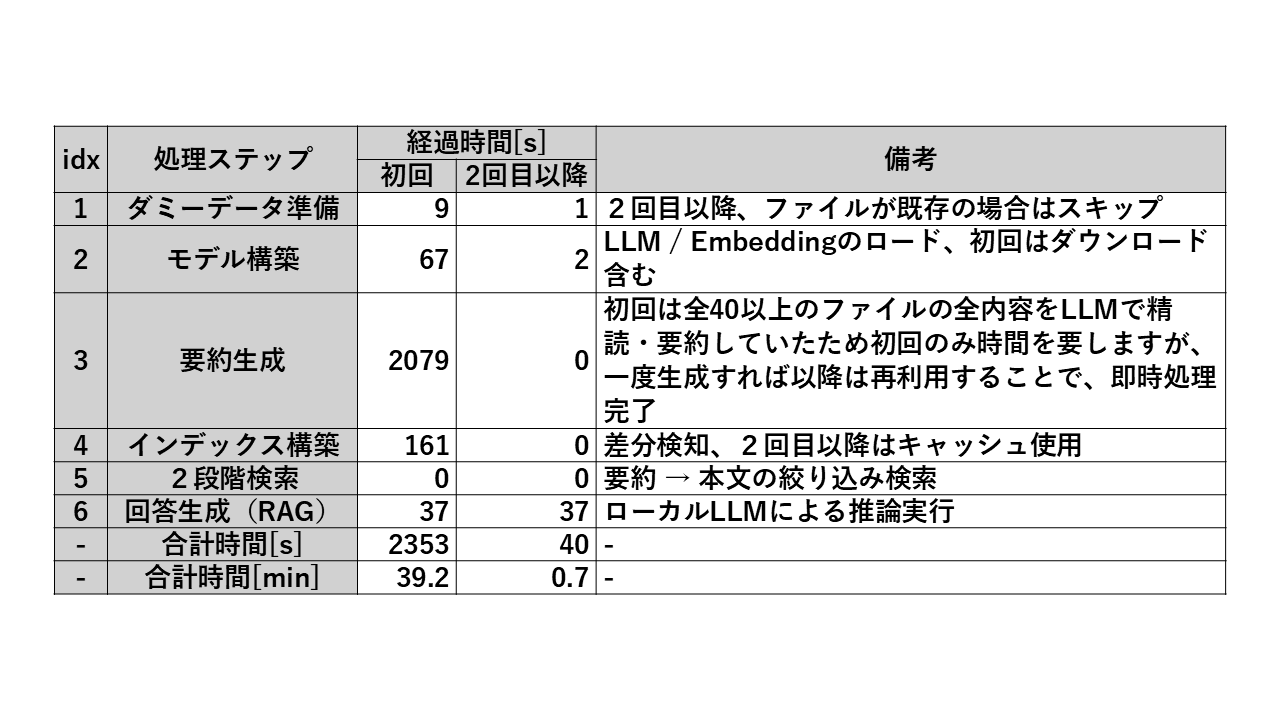
ネットワークの状況にもよりますが、最終的なバージョンにおける処理ステップ毎の処理時間実績は以下です。(初回のみ実行必要な、要約生成(複数のドキュメントに対して一つ一つ要約を生成する処理)およびインデックス構築については、ノートPCのCPUのみというマシンパワーの関係上、どうしてもAPIのほうに軍配が上がります。)
なお、当該ハンズオンについては、以下環境で動作することを確認済みです。
- Windows 11 Pro 64 bit / Intel core-i5-1135G7 / 16GBメモリ(一般的なビジネスノートPC相当)
- Arch Linux (hyprland) x86_64 / AMD Ryzen 7 6800U / 32GBメモリ(少し余裕を持った個人開発仕様)
苦労した点と学び
今回の検証にあたって、特にAIの生成品質に関する課題に直面しました。
1. 「回答の無限ループ」という壁(プロンプトの罠)
ローカルLLMを動かした際に、モデルが「質問」や「回答」のセクションを何度も繰り返し生成してしまい、出力が止まらなくなる問題がありました。
- 苦労した点:モデルのパラメータ設定だけでは制御しきれず、生成が止まらないことです。
- 学び:単に「簡潔に回答を」と指示するだけでなく、停止シーケンスを明確に定義し、プロンプトの構成自体を「モデルが区切りを認識しやすい構造(--- や 回答: のようなメタ情報)」にする重要性を学びました。これは「RAGの精度はインデックスの検索精度だけでなく、LLMの入出力インターフェースの設計に大きく依存する」という学びが得られました。
2. 回答の「精度」と「引用」のバランス
初期段階では、モデルが資料をそのまま長く引用してしまい、求める「結論から述べる」回答になりませんでした。
- 苦労した点:資料からの過度な引用を抑制し、かつ根拠を明示させるという、相反する制約をモデルに守らせるのが難しかった。
- 学び:「結論から簡潔に」「資料の要約を行う」「参照元を文末に記載する」という制約条件をステップバイステップで指示(プロンプトを構造化)することで、モデルの挙動が劇的に改善しました。これは「AIに指示を出すことは、他者への指示出しと同じくらい言語化能力が求められる」という学びが得られました。
3. パフォーマンスの最適化
初期実装では、1件ずつ順次インデックスに追加していましたが、これでは40件以上の登録に数分を要する実用性の低さに直面していました。
- 苦労した点:逐次処理によるEmbeddingのオーバーヘッドで、43件の登録に4分以上要する実用性の低さに直面していました。
- 学び:IngestionPipeline によるバッチ化とDB参照による差分更新を導入し、更新なしなら「1秒未満」で起動する運用設計の重要性を実感しました。
活用可能性と今後の展望
当該リポジトリは、参照するデータや検索クエリ、プロンプトの変更を行うことで、例えば以下業務シーンへの応用が可能と考えています。
- 社内規程検索bot:膨大なマニュアルや規程集の中から、該当箇所を特定し、対応策を模索する。
- 議事録のナレッジ管理:過去の会議資料をRAGで横断検索し、意思決定の経緯を迅速に調査する。
(元々は、社内で取り組んでいる契約書チェックエージェントにて、入力となる契約書に対し、決まったプロンプトやフローで処理することを想定)
結び
完全ローカルRAG環境の構築は、社内のナレッジ流通をより安全かつ迅速にするための強力な武器になります。今回の開発で確立した設計思想は、今後の大規模なDXプロジェクトにおいても、汎用的な知見として還元できると考えています。
技術は使われて初めて価値を持ちます。まずは手元のドキュメントを検索する体験から、ぜひ現場の皆様と一緒に、次世代の業務インフラを形作っていくことができればと思います。
