












- 大規模言語モデル(Large Language Models、以下、LLM)による数値データの解釈や可視化といったデータ分析業務について、実務レベルで支援可能な範囲を検証
- JEPX市場価格を題材に、気象要因などと結びつけた時系列データの解釈をLLMに行わせ、その妥当性を確認
- Function Callingを用いてユーザーの指示に応じて必要なデータ抽出と適切な可視化をLLMが選択可能であることを立証
- LLMは説明性向上や示唆抽出を支援する分析アシスタントとして有効であることを確認
こんにちは!TSUNAGU Community Analytics(以下、TCA)でAIモデルの構築やデータ分析を担当しているものです。
今回は数値データの解釈や可視化といったデータ分析のコアな作業に対してLLMの貢献度についての調査結果を共有します。
モチベーション
現在、種々の業務についてLLMもといAIエージェントが、我々の日々の作業を代替することが当たり前となっています。一方で、実務レベルで活用されている範囲は、その汎用的な自然言語処理能力に力点が置かれ、社内ルールや既存の問い合わせ内容をナレッジとして活用した社内チャットボット作成や、会計データの自動仕分けなど、自然言語によって処理できる範囲が主流でした。そうした中で、近年では自然言語的な文脈から外れ数値データの解釈といったことに実務レベルで取り組んでいる例も見受けられるようになってきています。データ分析を強みとしているTCAでもこういったデータ分析領域へのAIエージェントの活用は積極的に行っていきたいと考えています。
TCAでは数値予測をするAIモデルを複数クライアント向けに運用しており、様々な予測値を配信しています。ここで問題視されるのは、その予測値がどのような要素を考慮して算出されているのかといった、説明性に関わる箇所です。レスポンシブルなAI運用をするうえでここは避けて通れない課題です。
それに対する回答として、TCAではモデルが考慮している情報をまとめたレポートを配信し、様々な図表や指標をもとにモデルのホワイトボックス化を行っています。しかし、複雑な事象を予測するモデルでは考慮する情報も多くなり、必然レポートに記載される情報量も比例して増えていきます。この理解と解釈をAIエージェントがサポートすることで人間の認知的負荷を軽減できれば、ホワイトボックスなモデル運用の利点をフルに活かせるのではないかと考えています。
さらに、モニタリングをしていく中で定型的な要素だけで判断できることは少なく、様々な切り口からモデルの予測値を解釈したい、というニーズも発生します。これに対してはモデルの諸元データや予測値をtableauなどの可視化・分析できるようなツールで確認できるようにし、利用者側で分析できる環境を構築することが解決策の一つですが、作業者ごとに分析に関する知見も異なるとすると、モデルの予測値の解釈もAIエージェントによるサポートが効果を発揮する箇所と言えます。つまり、モデル運用の中で、大量のデータに対して示唆を抽出しつつ、新たな分析観点も提示できる「データ分析をサポートするAIエージェント」の価値が極めて高いと言えます。
それではさっそく
今回はTCAが関わりの深い電力関係のデータの中でも、電力需給のかなり幅広い要素から影響を受けて決定されるJEPXの市場価格について、AIエージェントを構成する一要素であるLLMの分析サポートの範囲について検証したいと思います。
以下二つの観点でLLMの動作を確認してみました。
① JEPXの市場価格の時系列データを需給と結び付けて説明できるか?
② ユーザーの要望に沿った可視化を提案できるか?
JEPXの市場価格の時系列データを需給と結び付けて説明できるか?
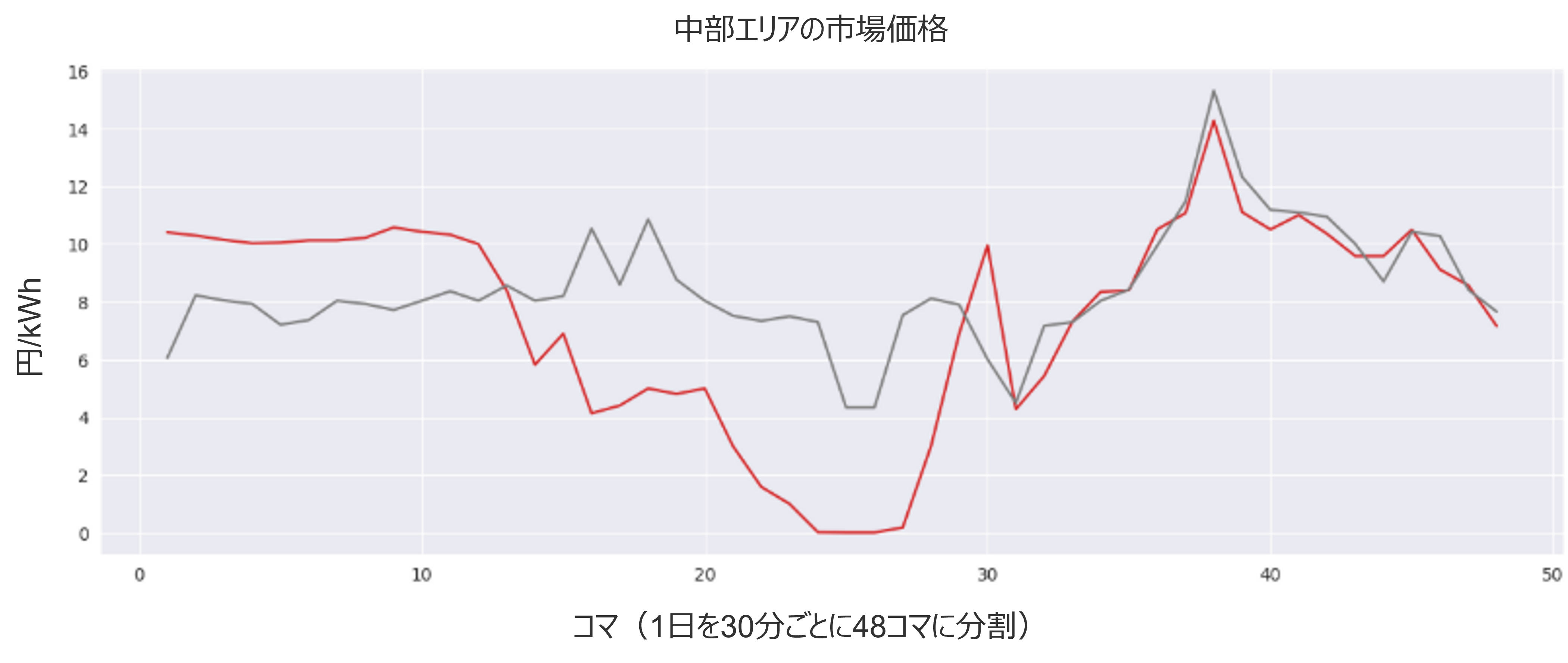
以下の図は2025/5/13(赤線)と2025/5/12(黒線)の中部エリアのJEPXの市場価格です。この5/13は日中の時間24コマ目付近では0.01円に近い低い価格をつけていますが、前日の5/12はそこまで低い価格をつけず、おおよそ火力発電による発電限界費用レベルの水準を保っているようです。なぜ5/13がこのような価格水準になったかを、5/12からの変化を軸に日射量、気温、降水量といった気象の変化に着目しながらLLMに説明させてみましょう。
LLMに解釈させるうえで最も重要なのはプロンプトの構成ですが、今回は数値データをインプットするうえで中間の文脈が無視されてしまうこと(Lost in the middle)を懸念して、コマごとに一度LLMに説明させて48コマごとの分析説明を作り、最後にその48コマごとの説明を要約させる以下のような手法で解釈を実施しました。
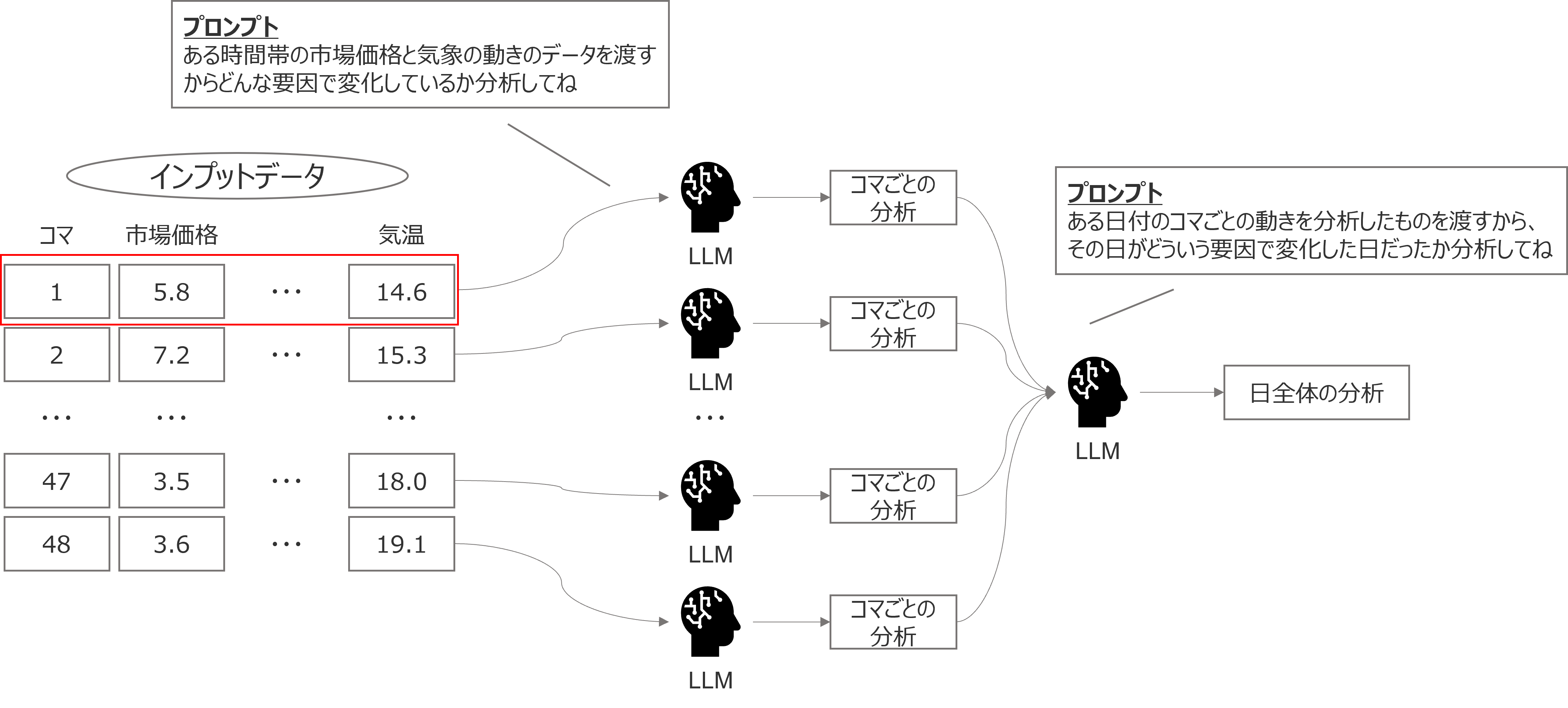
検証当初は、LLMがテーブルデータを分析できるのかが未知数だったこともあり、またLost in the middleの話題も活発だったため、今回はやや複雑なフローを組みましたが(筆者がちょっと凝ったことをしたかっただけという話もあります)、現在ではLong Context LLMということも言われるように長い文脈をすべてインプットする方が精度は向上するのではないか、という話もあるため48行程度のデータであればここまでおぜん立てする必要は必要ないかもしれません(他の分析では、今回の検証より大きなデータをLLMに読み込ませても一定の説明をしてくれています)。
話がそれましたが、上記のフローを組んだうえで得られた最終的な出力が以下になります。

概ねそれらしいことを言えているようには見えます。実際のデータを見ながらLLMの分析の是非を確認してみます。
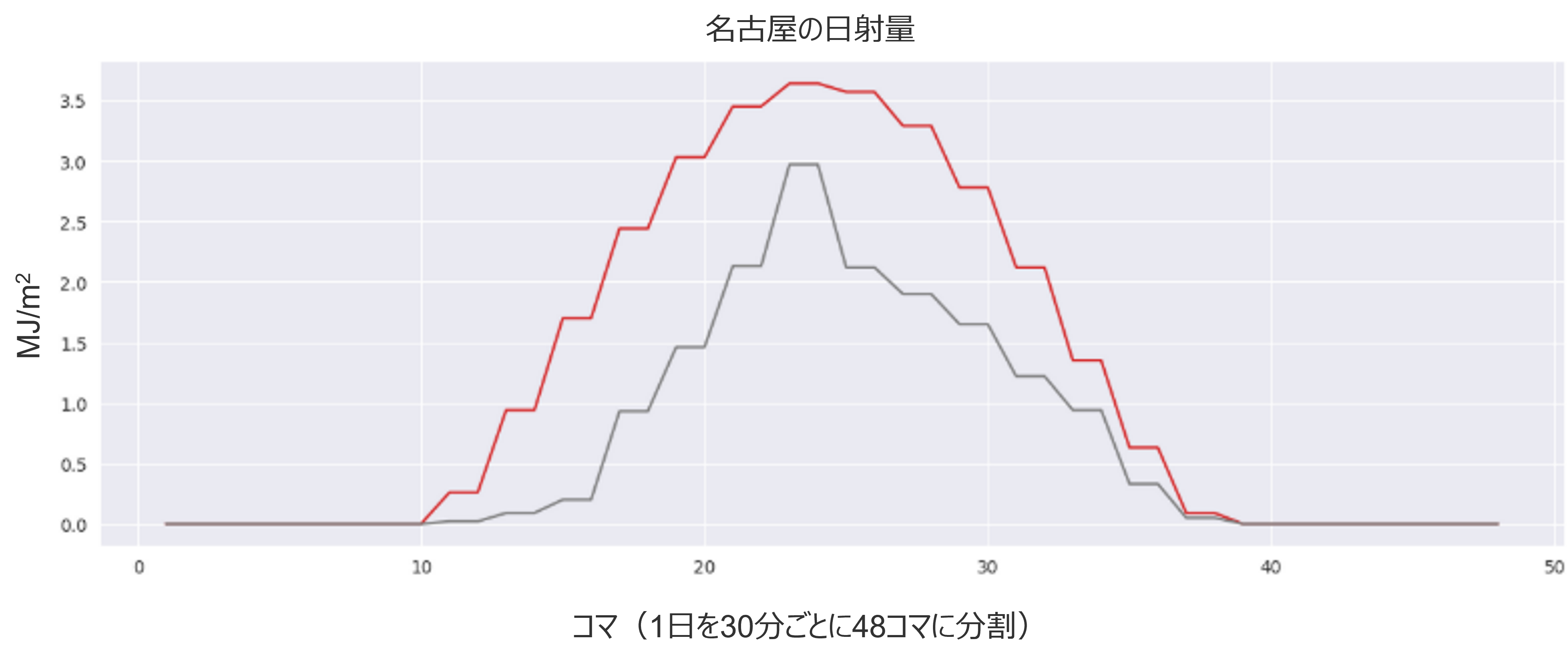
まずは日射量を見てみましょう。以下に5/12と5/13の名古屋の日射量を示しますが確かに5/13は日射量が多く太陽光発電量の増加も期待できるため、価格は下落しやすかったと言えるでしょう。
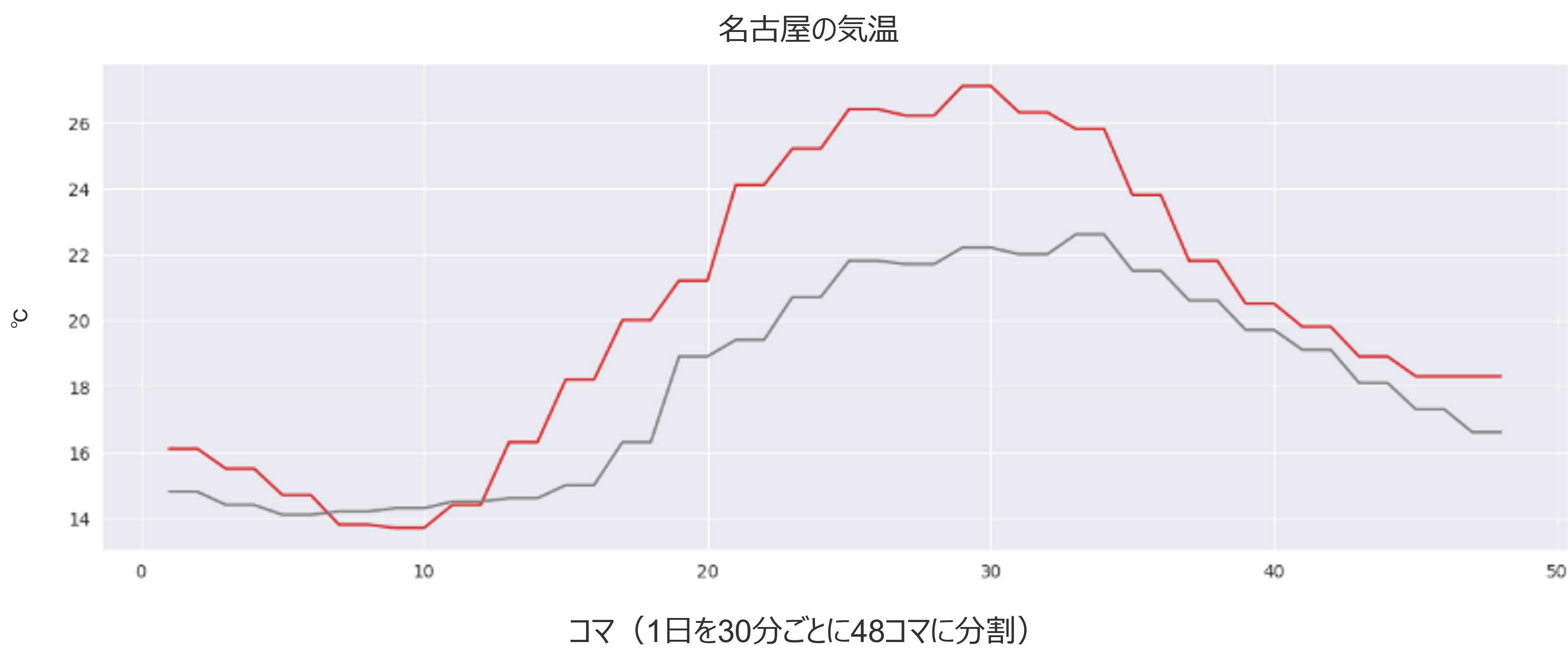
次に触れられているのが冷房需要ということで気温についても見てみましょう。以下が同じく名古屋の気温の比較ですが、5/13はかなり気温が上がった日でしたので冷房の稼働が高まったという理由付けは気温の変化に対しての理由付けとしては大きくずれていないように思えます。
上記は簡易的な検証ではありますが、さらにプロンプトなどを工夫することや、専門家の知見をインプットするより実務に近い観点からの分析が行えると考えます。また、実際の市場価格は他エリアとの連系線の接続状況に大きく左右されるので、それに関するデータや、気温と需要の正確な関係を数値化して教えることで冷暖房に関する言及もより正確になると考えられます。
ユーザーの要望に沿った可視化を提案できるか?
さて、分析に必要なデータを渡すとLLMがある程度それを正しく理解できることは分かりました。次に、一歩踏み込んで、”ある分析観点を与えた時に、LLMが必要なデータを集めてきて、適切な形で可視化できるのか?”を検証したいと思います。
現在筆者はOpenAIのAPIを使って検証を行っていますが、基本的にLLMにはFunction Callingと呼ばれる機能が備わっており、あらかじめいくつか道具を渡しておくと、指示が来た時にその道具を組み合わせながら問題解決を図らせることができます。この機能を使って、与えた分析観点について適切な可視化を実行させるようなプログラムを作成してみます。
まず今回は、単純に時系列データをプロットする関数と、相関をプロットする関数の2つを道具として与えたうえで、下記の2点について検証します。
① 必要なデータを抽出できるか?
② 必要な可視化を選択できるか?
なお、検証には以下のデータを使用しました。

それではLLMに指示を出してみましょう。今回は「2025年4月2日の中部エリアのエリアプライスと太陽光発電量の相関を可視化したい」という指示を与えます。事前に2025年のデータをすべてインプットするので、LLMとしては可視化する期間をスライスする作業も必要となります。これによって得られたのが以下の可視化です。
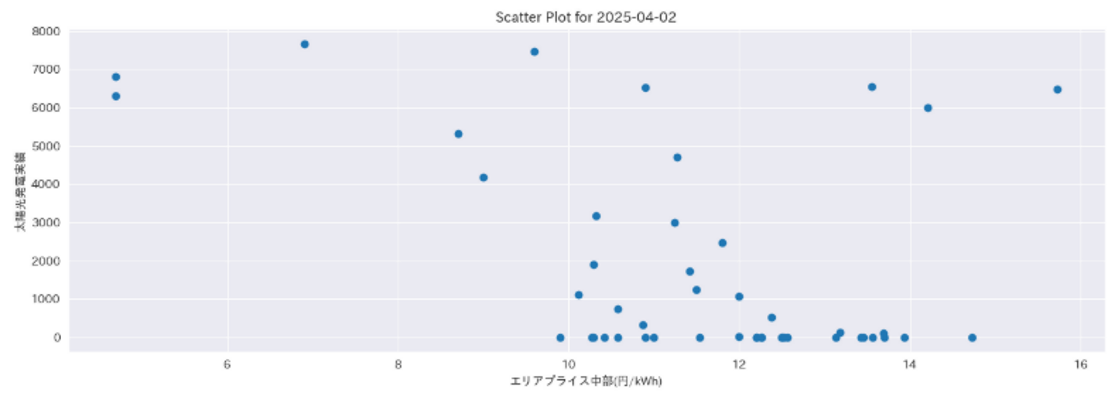
相関をみるために散布図が選択されているという点と、プロットするデータとして太陽光発電量と中部エリアプライスを選択されているという点で必要な情報を可視化できているといえますし、適切に一日分のデータを取得することもできているようです。与える関数の自由度をあげることでさらに高度な可視化も可能なため、簡易な分析には十分対応できる可能性がありますね。
おわりに
いかがだったでしょうか?今回の検証では、データや適応範囲を絞っているものの一定データ分析に必要なデータの理解や分析方針の策定といったことをLLMが代替できる可能性が示されたと思います。
今後はさらに複数の可視化手法を与えることや、勾配ブースティング系のモデルのホワイトボックス化で使われるSHAP値の分析にもトライさせることで、モデルのモニタリングやデータ分析をLLMが担うことができるようになると思いますので、引き続き検証を進めたいと思います。
注釈
- JEPXの市場は日本の場合、北海道、東北、東京、中部、関西、北陸、中国、四国、九州の9エリアに分かれており、それぞれ異なる価格が付きます。(エリア間の連系線がつながっている場合はそのエリア同士は価格)
