












- 技術記事やレポート執筆においてボトルネックになりがちな「情報収集」と「思考整理」を、ローカルLLM(大規模言語モデル)とMCP(Model Context Protocol ( AIアプリケーションと外部システムを統一的な方法で接続するためのオープン標準))を用いた個人専用AIエージェントによって自動化・高度化する取り組みを紹介
- ニュース、論文、レポートなどを非同期で自動収集し、翻訳・要約・メモ化までをローカルLLMで処理することで、APIコストを抑えつつ大量のインプットが可能
- 情報の蓄積単位を「記事」ではなく「知識の断片(メモ)」にすることで、横断的な比較や構造化を実現
- AIエージェントを用途特化型にすることで、調査から構成案作成、ドラフト生成までを一気通貫で支援する、“対話可能な編集者・壁打ち相手”としての活用有効性を示唆
こんにちは。日々、技術記事やレポートを書く中で「調査と構成案づくりに時間を取られている」と感じることはないでしょうか。企画書作成、提案資料、技術動向調査、レポート作成など、技術的なアウトプットを行う際には「調べる・整理する」作業が業務時間の多くを占めがちです。
今回は、国内外のニュース・論文・レポートを自動収集し、知識を蓄積し、思考整理の壁打ちまでを一気通貫で支援する「個人専用AIエージェント」を、ローカルLLMとMCPを使って構築した事例を紹介します。
この記事では、以下を中心に解説します。
• 汎用AIエージェントではなく「特化型」を作った理由
• 仕組み全体の設計思想
• 実装して分かった現実的なノウハウ
はじめに:AIエージェントは「自分専用の研究チーム」
「AIエージェント」という言葉をよく耳にするようになりましたが、実際に何ができるのかは分かりづらい部分もあります。
私の理解では、AIエージェントとは、「あなたが寝ている間に設定した国内外の情報ソースを読み込み、重要なポイントを付箋にまとめ、翌朝、執筆中のあなたの横で的確な資料を差し出してくれるアシスタント」のような存在です。これまで人が数時間かけて行っていた「情報収集 → 要点整理 → 構成案作成」を、AIが人間の作業の裏側で非同期に進めてくれるイメージです。
今回構築したのは以下の仕組みであり、使うたびに、「手元に専属のリサーチアシスタントと編集者がいる」という感覚があります。
• 日本国内外のニュース・論文・レポートを毎日自動収集
• ローカルLLMで翻訳・要約・メモ化
• エディタに統合されたCLIエージェントと対話しながら「テーマ出し → 構成 → ドラフト作成」まで実施
話題の汎用AIエージェント「OpenClaw」との違い
最近では、ローカルで動く自律型AIアシスタントとしてOpenClaw(旧: Moltbot)のようなツールが注目を集めています。
では、今回自作した仕組みは何が違うのでしょうか。

調査や執筆を行う際に単発の指示よりも「同じテーマを何度も掘り下げ、再利用する」ケースが多く、その点で特化パイプライン型が有効でした。OpenClawが 「有能な秘書」 だとすれば、この仕組みは 「大量の文献を読み込む研究室の助教」 です。このような活動では「継続的に一貫性を持って支援する」点が重要です。
用途を「調査と執筆」に特化することで、コスト・品質・再現性のバランスが向上したと感じています。
※OpenClawの具体的な利用形態や得意領域は、設定や利用者の使い方によって異なります。
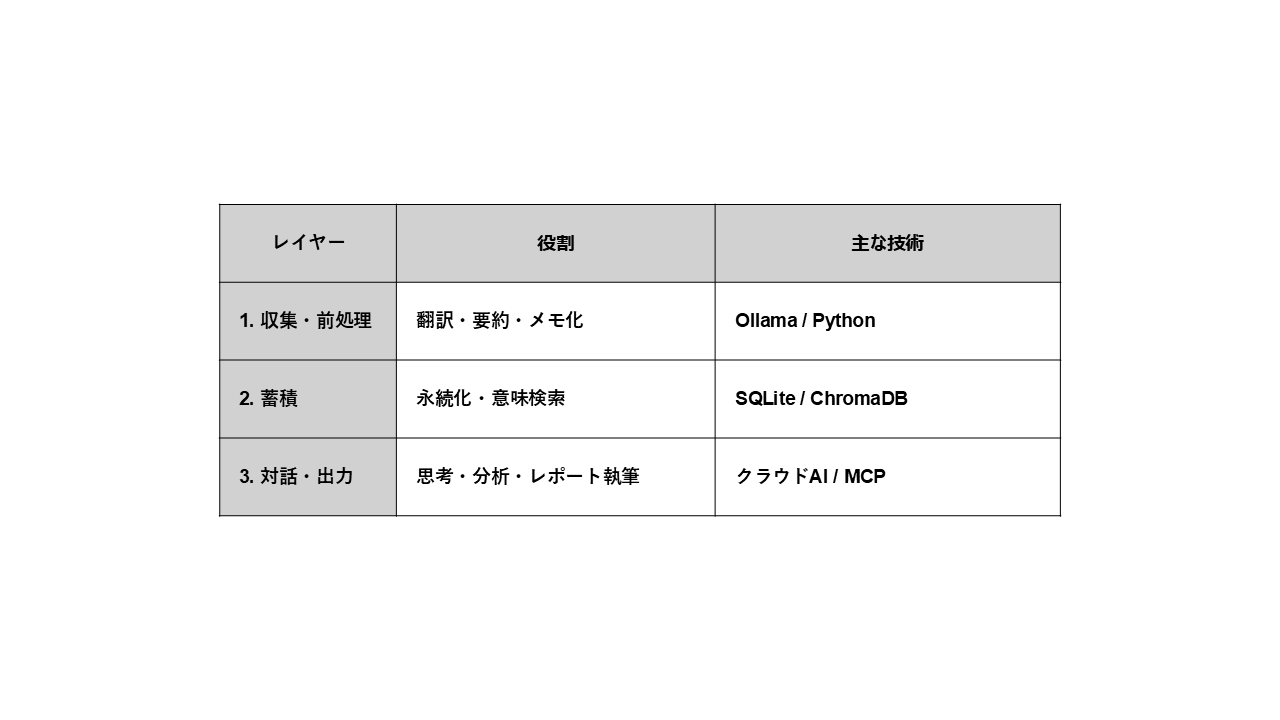
仕組みの全体像:3つのレイヤーで分業する
技術の話に入る前に、役割ベースで整理すると以下の分業になります。
• 大量の情報を読む作業:AIに任せる
• 考える・判断する作業:人とAIの対話で行う
• 保存・検索:事後的に使える形で蓄積する
処理ボリュームが大きい前処理はローカルLLMに任せ、文脈理解とアウトプットはクラウドAIに任せる、という設計思想です。
※この流れはすべて裏側で自動実行され、利用者はエディタ上でAIと対話するだけです。

これを実現するために、以下の技術構成を採用しました。
1. 収集パイプライン:API課金を発生させず大量に処理する
収集している情報源
現在は以下の3系統を自動収集しています。
• RSSニュース(毎日) 日本国内外の技術ニュース
• レポート(週次) 各種機関の出しているPDFファイル群
• arXiv論文(週次) AI関連論文の abstract のみ保存
ローカルLLMを使う理由
翻訳・要約・メモ抽出はすべてローカルLLMに任せています。理由はシンプルで、APIコストを抑えられるからです。月に数千件の記事を処理すると、クラウドAIだけでは現実的なコストになりません。
一方、ローカルLLMは翻訳などのタスクに限定すれば実用的に動作し、前処理としては過不足ない品質を出してくれます。
2. データベース設計:記事ではなく「メモ」を扱う
蓄積レイヤーは二段構えを採用しています。
• SQLite:記事原文・メタデータ
• ChromaDB:メモの意味検索
ポイントは、分析単位を「記事」ではなく「知識の断片(メモ)」にしたことです。1つの記事から、LLMが以下のような短いメモを複数抽出します。
• fact(事実)
• claim(主張)
• trend(傾向)
• contradiction(矛盾)
情報を集約する際にLLMが読むのは、記事全文ではなくこのメモ群です。これは、会議メモや付箋を使って思考を整理する人間のやり方に近い設計です。
これにより、以下の効果が期待できます。
• コンテキスト消費を大幅に削減
• 記事横断の比較・矛盾検出が容易化
3. MCP統合:AIエージェントを「編集者」にする
本仕組みでは、このMCPを検索機能のみに限定することで、AIが“勝手に判断する存在”ではなく、人の意思決定を支援する道具として振る舞う構成にしています。MCPを使って、データベースをエージェントCLIに接続します。本仕組みでは、MCPサーバーは検索機能のみに役割を限定し、分析や判断はすべて対話側のAIモデルに任せます。
• MCP側:「このキーワードで検索して結果を返す」
• AI側:「どう解釈し、どう構成するかを考える」
この分離により、モデル変更やプロンプト改善のコストを最小化できます。
あとはエディタ上で「ここを短く」「導入を強く」とAIに指示しながら、壁打ちしたり思考を整理したりします。
やってみて分かったこと
• ローカルLLM × クラウドAIの分業
量の処理はAPI課金の発生しないローカルLLMに任せ、文脈理解や最終アウトプットはクラウドAIに任せる、という割り切りが有効
• プロンプトは「育てるもの」
コードと同じく、バージョン管理しながら改善していくと品質が安定
• RSSは意外と壊れやすい
特に海外サイトは定期的な死活監視が必要
まとめ
この仕組みを作ってから、「最新動向のリサーチと構成案出し」 が効率化されました。インプットはすべて非同期で処理され、書きたい瞬間には、すでに数千件の知識を蓄えたAIエージェントがいます。人間は最後に「人間らしく整える」ことに集中するだけです。DXに限らず、AI活用の本質は、業務そのものをAIに置き換えることではなく、人が考えるための時間をどう作るかにあると感じています。
AIエージェントの本質的な価値は、単なる会話ではなく、自分専用の知的パイプラインを作ることができることだと実感しています。(ちなみに、この記事の叩き台自体もこの仕組みで生成しました。)
TCAは引き続き、先端技術も取り入れながら、新たな価値を創出する取り組みを進めて参ります。
Let’s Enjoy DX!
